Two People You Need for Building a Strong Analytics Team
Eugene Khazin
Principal and Co-Founder, Prime TSR
I can’t go two weeks without seeing an article about how a “data scientist” is the hottest job in America. And, trust me, I see the need first-hand through my client visits.
It makes sense. Companies have a lot of data they want to make use of. So they kick off their analytics program and build a big data and analytics team to create an advanced analytics model. It makes sense, but it doesn’t always work.
The truth is that companies want analytics, but they make a huge mistake upfront when starting their analytics program: The data isn’t ready for the data scientist to do their job, which causes the data scientist to be hugely unproductive.
So, that’s a big reason I decided to sit down and write this article.
You have two options when you’re building an analytics program and/or machine learning initiatives:
Hire someone who ingests and transforms data to enable data scientists to work on their use-cases.
Hire someone who has a statistics background to utilize machine learning models and artificial intelligence to create advanced analytics.
You can’t do #2 without doing #1 first. I mean, you can, but it won’t end well. I’m just here to stop the trainwreck before it starts.
What is a data engineer and why would you hire them?
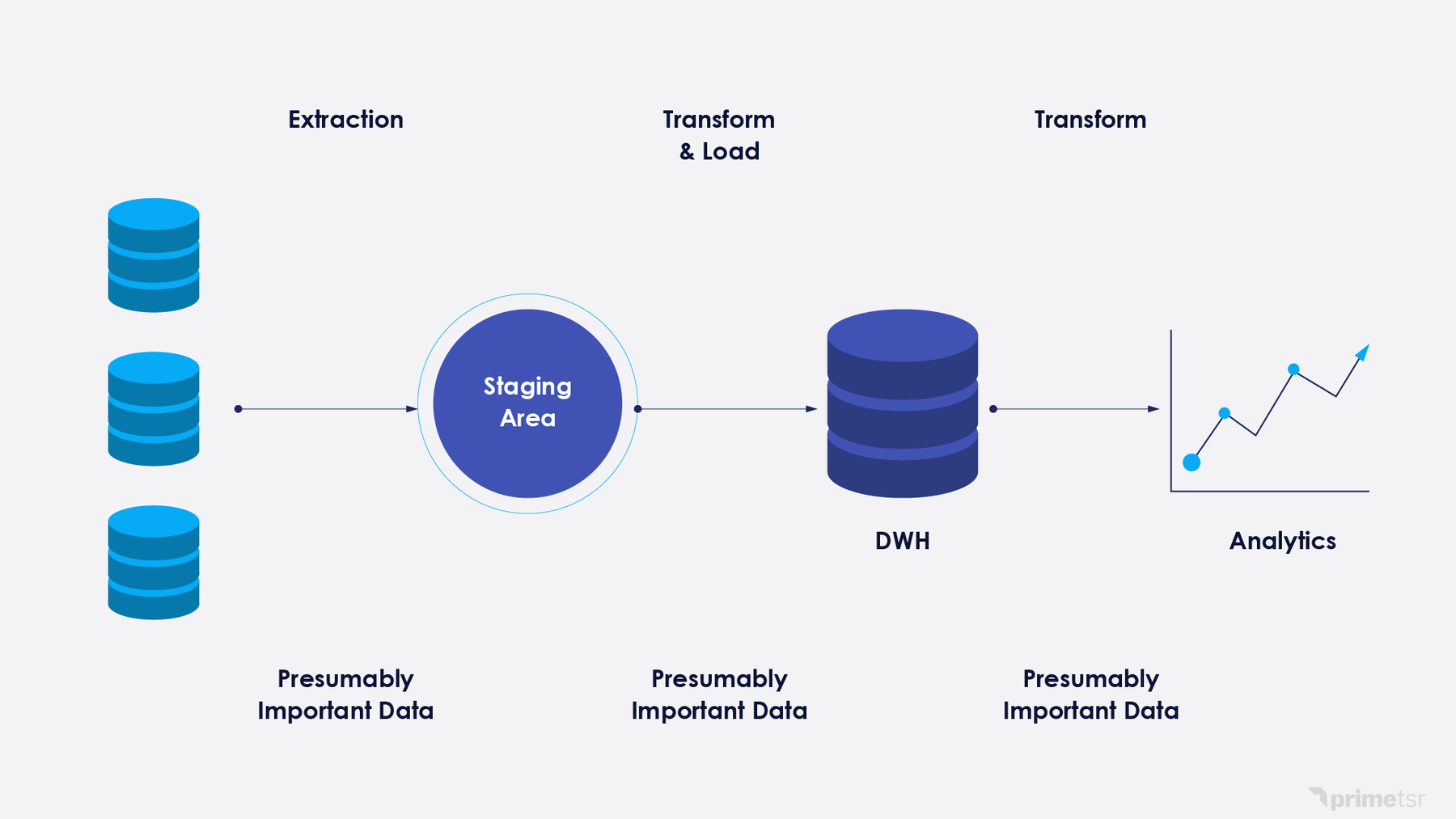
A data engineer also called an “ETL developer” is a software engineer whose primary responsibility is to work with structured and unstructured data to build data pipelines that can be used for analytical or operational use cases.
You hire a data engineer, or a team of data engineers when you need the right data from various systems in one centralized location.
The steps below refer to what must be undertaken to collect data from a variety of sources and put them into one central location that others can use in a specified format.
Since they are developers, the majority of their time is spent in front of the computer building the data models and structures that others will use. This may involve using specialized tools (such as Spark) or standard tools (such as SQL).
Data collected by a company needs to be translated into a format that is easy to understand. People naturally understand pictures in forms of charts and graphs better than they would understand raw data. To be an exceptional data scientist, one must be able to use data visualization tools to convert complex data into a format that is easy to understand and communicate.
Kate Strachnyi
Founder, Story by Data
What separates a great data engineer from the rest?
A great data engineer is diligent at making the data match the business requirements while not necessarily trying to understand what story the data is trying to tell.
A good data engineer can ingest and transform data into a database, but a great data engineer has a deep understanding of the metrics and analytics the data scientist is looking to analyze. When done right, a data engineer has the right data in the right context for the data scientist to do their job.
A great data engineer knows their role when it comes to manipulating and normalizing data. They understand that the more organized the data, the better everyone else could do their job.
What is a data scientist and why would you hire them?
A data scientist takes the data from one or more databases the data engineers have created and applies mathematical algorithms to it in order to extract insights and/or make predictions from the data.
For the record, I don’t think hiring a data scientist is a bad idea. I think it’s a great idea. It’s only a bad idea under the wrong circumstances and when you expect results that just aren’t achievable.
A data scientist must be able to do any (or all!) of the following:
Communicate, communicate, communicate. This is not a sit in the basement, run the numbers, and hope people understand it job. It requires SIGNIFICANT communication.
Work with business stakeholders and subject matter experts to formulate the problem and “clean” the data to make sure it can be used (i.e., make sure the data is free of errors).
Explore the data to uncover insights, develop machine learning models, iterate with the stakeholders to ensure the solution satisfies the objective, and possibly aid in the model’s deployment.
There is considerable leeway in each of these steps, however, because data scientists should be considered more as mathematicians than software developers. In addition to a solid knowledge of modeling techniques, they should be able to work with non-specialists to understand the problem and communicate their results back.
Depending on the seniority of the data scientist, they may spend the majority of their time at their computer writing scripts in programming languages such as R and Python and inspecting data (junior and mid-level), or in meetings with stakeholders and executives on making sure the data science efforts are benefiting the company (senior and team leaders).
Great data scientists, when interviewing for a job, will ask a prospective employer about the data and data engineers they’d work with. If they don’t like the answer, they’re unlikely to accept any offer. No data scientist wants to find themselves in a situation where they can’t do good work, through no fault of their own.
Mark Meloon
Senior Data Scientist, Service Now
What separates a great data scientist from the rest?
Good data scientists should be able to tackle a problem from start to finish using the above steps. Still, data science is very tricky and it’s amazingly easy to make mistakes that go undetected. Truly great ones not only have more experience to know what can go wrong (and how to correct it), they also have a mindset that is ever vigilant.
One truly great data scientist I know says that whenever she generates a result, the first thing she asks herself is, “What’s wrong with this?”
Great data scientists also do an excellent job of communicating their results and methods to non-experts. It still amazes me how many data scientists can’t describe simple concepts like overfitting and data leakage in plain English.
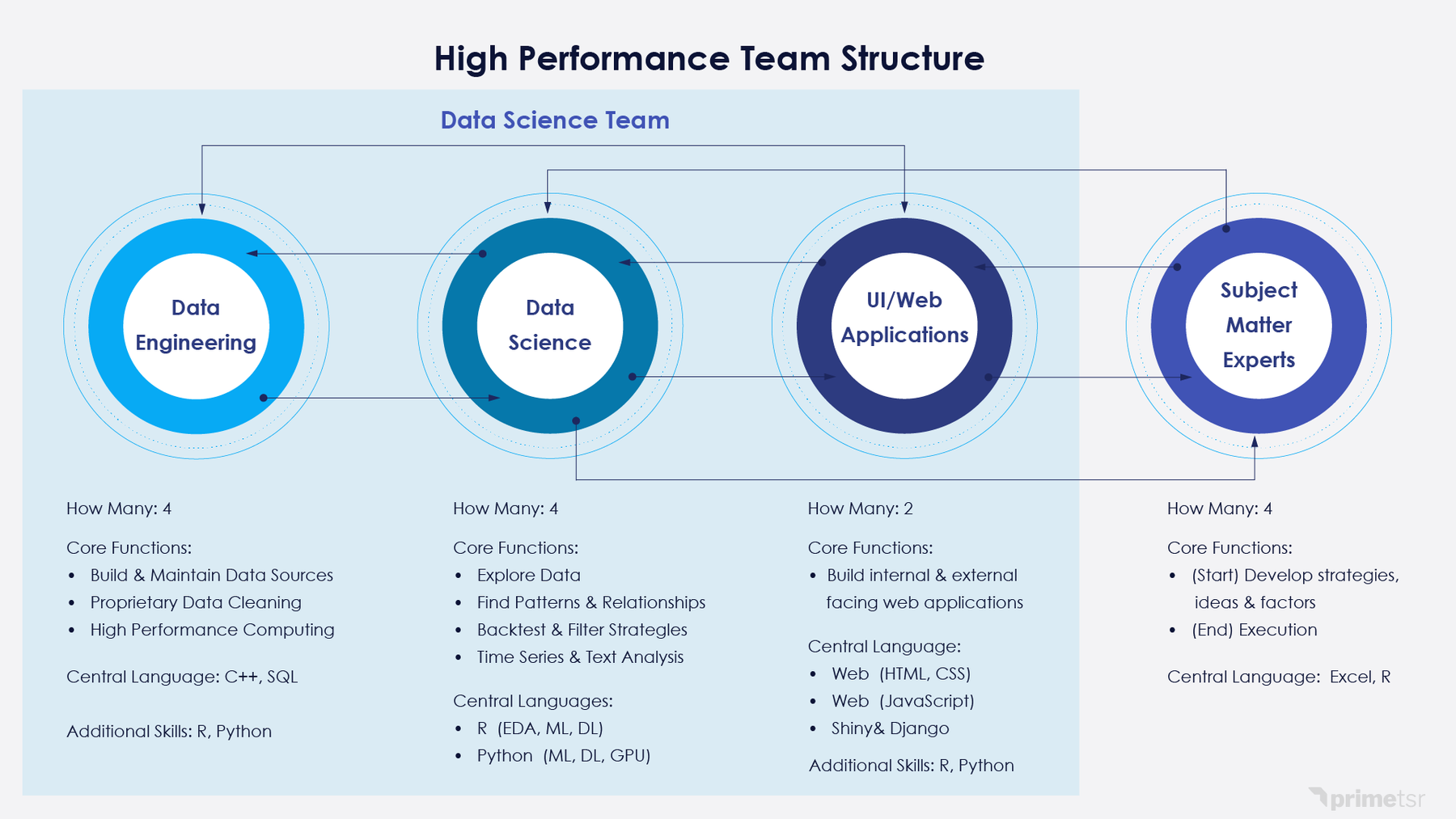
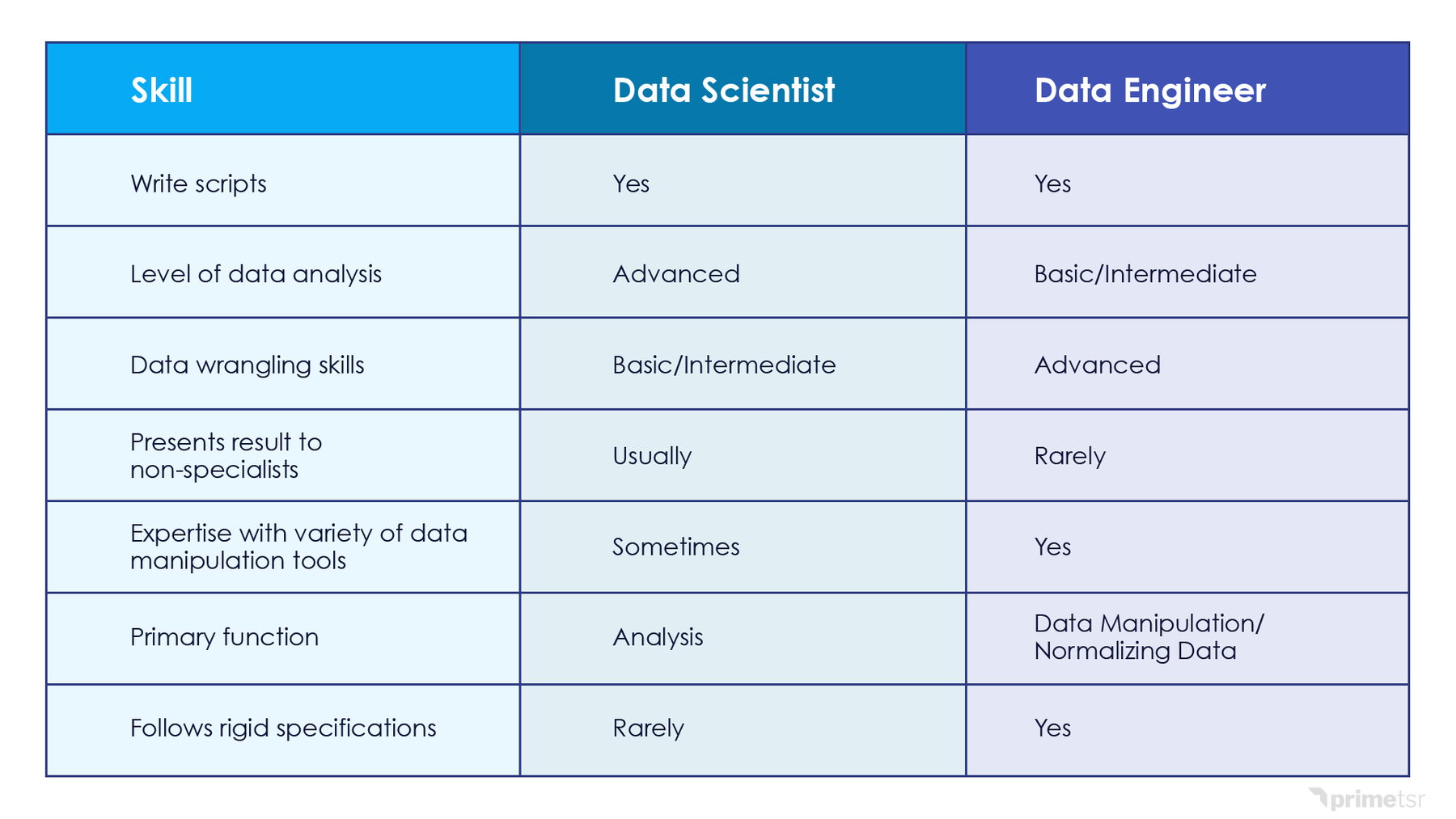
What’s the difference between a data scientist and a data engineer?
Data scientists will need the data in one or more tables in a database and in a “reasonable” condition. That is, the number of obvious errors should be at a minimum (e.g., a sequence of letters for a customer’s age) and the data scientist should not be expected to pull data directly from devices (e.g., those connected via the Internet of Things). Basically, if you have the right data in the right place, you can hire a data scientist. Otherwise, you’ll need a data engineer first.
Note, this does not mean the data scientist should assume any data made available to them is error-free. An important part of their job is “cleaning” the data to make sure it is in a form needed by machine learning algorithms. For example, most algorithms cannot gracefully handle situations where some data is missing (e.g., some of the records of customers have missing ages). While there are many ways around this problem, the data scientist needs to think carefully about which to choose. For simple questions, data scientists are not needed.
What are the average sales in North Dakota? This may simply involve taking two columns and combining them with another table. A data scientist is certainly not needed for this.
Complex questions are where data scientists are the most useful. Here are a couple of examples:
Why are there trends for these sales? Are the differences between the North Dakota sales and are those for other states statistically significant?
Here’s how data scientists and data engineers work together
For data collection and answering simple questions about the data, data engineers will be sufficient. Once the data is prepared, the data scientist can take over to uncover deep insights and/or produce predictions. While the separation seems clear on paper, you must be careful to enforce this in practice.
Here’s a breakdown of skills:
With data science being considered the more “sexy” of the two roles, it is easy for overzealous data engineers to attempt to take on data science tasks. You may fall into the trap of having a data engineer point to the fact that they’ve taken a few online courses in data science and claim they are now in a position to “help out” your overworked data scientists. Without the necessary experience, this can lead to disaster.
On the other hand, if data scientists become looked at as the “data guys” in your department, you may be tempted to reach out to them anytime any data-related task is involved. But having data scientists answer easy questions and generate reports is not only a waste of talent, it can cause them to become disillusioned with the role at your company and look for a new job. You must also guard against data scientists playing anything other than an advisory role in creating the ETL data pipeline. They may have ideas on how to do it, but their input should be relegated to what the pipeline must provide, now how to do it.
As I mentioned before, it’s helpful to think of data scientists as more like mathematicians than software developers. They must have a clear goal for their work, which should be developed in conversations with business stakeholders and subject matter experts. While this may sound obvious, it’s very easy to just let a data scientist go and “find something interesting in the data.” Unless you have a dedicated budget for these types of explorations, they can get out of hand very quickly with little or nothing to show for them.
To summarize: If you have good data in a centralized location, then a data scientist can provide significant value to your organization. If not (e.g., your data is spread across legacy systems), you need to have a data engineer create a data pipeline before bringing a data scientist on board.
Also, if all you need from your data are answers to simple queries, a data scientist is not needed and, if you hire one, they will quickly become bored. You must also give data scientists a clear goal in their work to avoid efforts from ballooning out of control. Having data engineers and data scientists in your organization doing the jobs they are best suited for can provide you with new capabilities you would have thought otherwise impossible. Be clear on where you are now and where you want to be so you can avoid common pitfalls and make the most of the data revolution!
Now what?
What I’m hoping you extracted from this article is that although data scientists and data engineers sound similar, they are in-fact many different roles with little overlap in skill-sets.
Using this article to re-examine how you’re hiring for these roles will likely help you make better hiring decisions.
If you’re in the process of building a data strategy or need help determining what type of team you need in place to execute your strategy, please feel free to reach out to us.